Building Production RAG: An End-to-End Implementation Guide
From Prototype to Production: What It Actually Takes Most RAG tutorials stop at “put documents in a vector …


Enterprise AI has a completion problem. Not a capability problem — a completion problem.
Deloitte’s State of AI in the Enterprise report, published in January 2026, puts a number on what most engineering leaders already feel: nearly two-thirds of enterprise AI projects remain stuck in the pilot stage. They work in a demo. They impress in a quarterly review. And then they stall.
The models are good enough. They’ve been good enough for a while. GPT-4 shipped in March 2023. Claude, Gemini, Llama, and a dozen others have pushed the frontier further since. If raw model capability were the bottleneck, we’d see a different picture.
But 42% of enterprises say their AI strategy is “highly prepared” while simultaneously reporting they feel unprepared on infrastructure, data readiness, risk management, and talent. That gap — between strategic ambition and operational reality — is where pilots go to die.
The problem isn’t the AI. It’s everything around the AI.
Most pilot projects run on a laptop, a notebook server, or a single cloud instance spun up by whoever had time. It works for the demo. It doesn’t work for production.
Scaling an AI project means dealing with GPU orchestration, model serving, endpoint management, authentication, logging, monitoring, cost controls, and a deployment pipeline that doesn’t require the original data scientist to be in the room. That’s a different category of problem than getting a model to return good outputs.
The Deloitte data confirms this. Organizations report feeling unprepared on infrastructure even when they believe their strategy is sound. The strategy says “deploy AI across the enterprise.” The infrastructure says “we have one GPU instance and a shared Jupyter server with no access controls.”
What makes this worse is that most teams try to solve it piecemeal. They bolt on a serving layer here, a monitoring tool there, a separate authentication system somewhere else. Each addition works in isolation and creates a new integration surface to maintain. Six months later, the pilot that worked on a single node is buried under a stack of middleware that nobody fully understands.
The infrastructure problem isn’t about buying more compute. It’s about having a coherent platform where compute, tools, governance, and collaboration live in the same environment — so that moving from experimentation to deployment is a configuration change, not a re-architecture.
This is the one that should make executives uncomfortable.
Sixty-one percent of organizations say their data assets are not ready for generative AI. The data is unstructured, siloed across departments, inconsistent in quality, and governed by policies that were written for analytics dashboards, not for models that ingest everything they can reach.
Seventy percent find it hard to scale AI projects that rely on proprietary data. Not public data, not benchmark data — the data that actually makes an AI project valuable to the business. The proprietary knowledge that justifies the investment in the first place.
This is a compounding problem. A pilot can work with a curated sample. Production requires pipelines that handle messy, evolving, real-world data at volume. The jump from “we cleaned up a dataset for the proof of concept” to “our data is continuously available, governed, and fit for model consumption” is enormous.
Most organizations don’t need a data lake. They need the ability to connect, clean, and govern data where it already lives — inside a platform that treats data readiness as a first-class concern rather than a prerequisite someone else is supposed to handle.
RAG pipelines, embeddings, vector stores — these are table stakes now. The question is whether they’re integrated into the development workflow or whether they’re yet another separate system the team has to stitch together and maintain.
Here’s a number that should stop anyone building agentic AI: only one in five companies has mature governance for autonomous agents.
Meanwhile, only 8.6% of organizations have AI agents in production. Another 14% are still running agent pilots. The gap between what agents can do and what organizations are prepared to govern is wide and getting wider.
Governance isn’t a policy document. It’s an operational capability. It means knowing what an AI system did, why it did it, who authorized it, and what data it accessed — in real time, with audit trails, at scale. It means having guardrails that are enforced by the platform, not by hoping the team remembered to add them.
Most governance failures aren’t caused by malicious intent or even negligence. They’re caused by tooling gaps. The model runs in one system. The logs go to another. The access policies live in a third. The compliance team reviews a quarterly snapshot that’s already outdated by the time they see it. Nobody has a unified view of what the AI is actually doing.
The answer isn’t more governance meetings. It’s governance infrastructure — audit logging, policy enforcement, role-based access, and monitoring built into the same platform where the AI runs. When governance is an integrated capability rather than an afterthought, it stops being the reason projects can’t ship.
The talent problem is real, but it’s misunderstood.
Most organizations don’t lack AI talent. They lack AI operations talent. They have data scientists who can build a model and ML engineers who can fine-tune one. What they don’t have is the bridge between experiment and production — people who understand model serving, infrastructure, security, and the unglamorous work of keeping AI systems running reliably.
This is partly a hiring problem. But it’s mostly a tooling problem.
When the platform requires deep infrastructure expertise to move from development to deployment, you need specialists at every stage. When the platform handles the infrastructure — when the same environment that runs a notebook can serve a model, manage access, and produce audit logs — the existing team can take a project further before they hit a wall.
The Deloitte data shows organizations feeling unprepared on talent alongside infrastructure. These aren’t independent problems. They’re the same problem seen from different angles. Complex infrastructure demands specialized talent. Simpler, more unified infrastructure lets teams do more with the people they already have.
The pattern is consistent: organizations treat infrastructure, data, governance, and team capability as separate workstreams. They assign them to different departments, fund them from different budgets, and wonder why nothing connects.
AI projects stall when the team has to integrate six tools to get from experiment to production. They stall when governance lives in a spreadsheet instead of the platform. They stall when data pipelines are someone else’s problem. They stall when every deployment requires a specialist who isn’t available this quarter.
The companies that are moving past the pilot stage — the minority that Deloitte’s data identifies — aren’t doing it by being smarter about models. They’re doing it by reducing the number of things that have to go right simultaneously.
That means fewer tools, not more. A single environment where data scientists experiment, engineers build, governance is enforced, and deployment is a promotion — not a migration.
There’s no magic. There’s consolidation.
A team that can go from notebook to production inside the same platform — with data connectors, model serving, access controls, audit logs, and agent guardrails built in — doesn’t hit the same walls. Not because the problems disappear, but because the integration tax disappears. The effort goes into the actual work instead of into making tools talk to each other.
Calliope was built around this observation. Notebooks, agents, pipelines, AI models, and governance tools in a single browser-based platform, deployed on your infrastructure. The goal is straightforward: make the path from experiment to production short enough that projects actually finish.
Two-thirds of enterprise AI projects are stuck. The models aren’t the problem. The fragmented infrastructure around them is.
From Prototype to Production: What It Actually Takes Most RAG tutorials stop at “put documents in a vector …
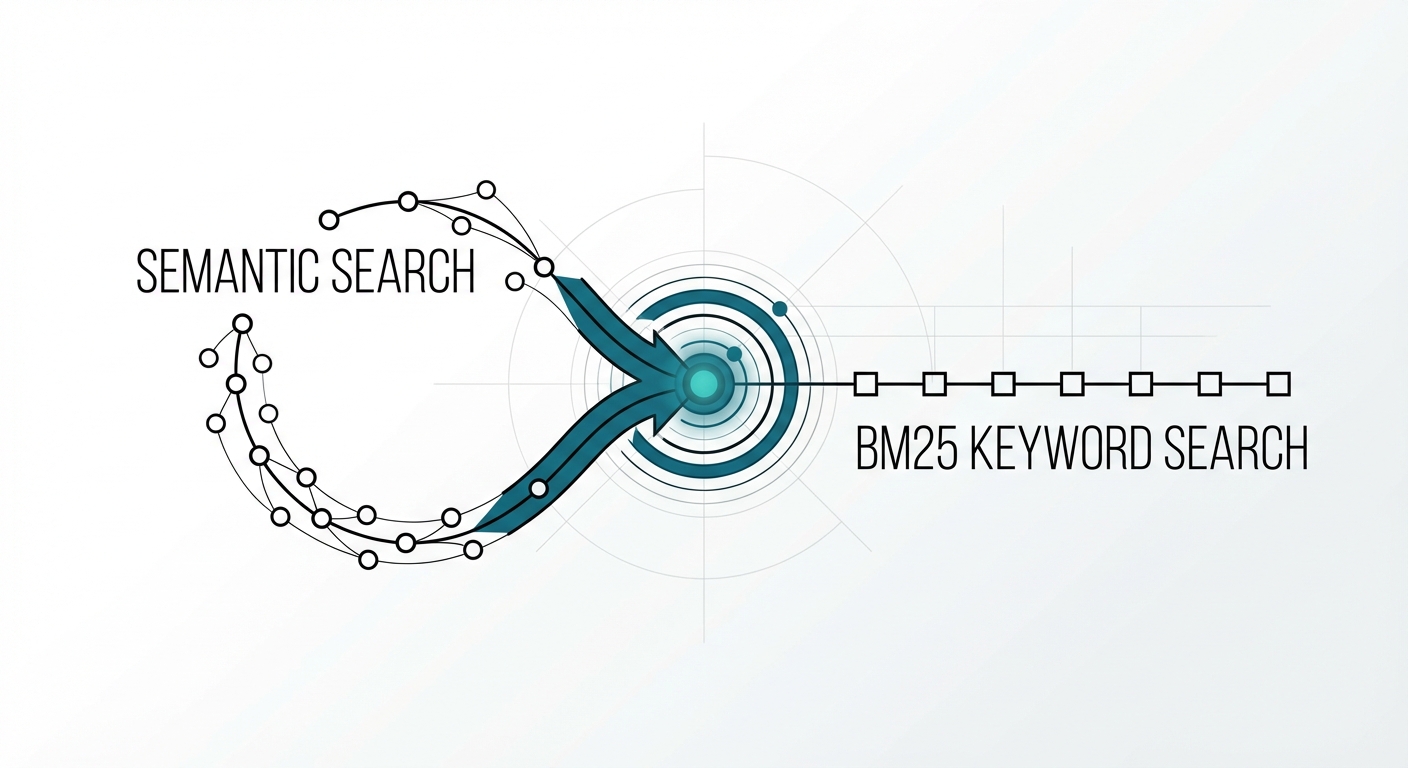
The Retrieval Problem No One Talks About You built a RAG system with a state-of-the-art embedding model. Semantic search …